AWS ALB Routing Algorithm Performance
Certain AWS components (and cloud components in general) do amazing jobs at simplifying our lives as developers who just want their infrastructure to be there. I can have a first-class layer 7 load balancer ready to use in my application within seconds. On the flip side, when abstracted technology is so readily available to you it might at the time seem indistinguishable from magic! AWS ALBs may fall into this category for you. I’ve had large and small implementations and architecture just simply work with ALB infrastructure with little changes to the defaults.
In more recent development and deployment of a new service, one of our teams encountered what looks like an unbalanced set of HTTP requests coming through the load balancer.
The Problem
As a part of standing up a new service, the team performed a series of simple load tests that performed standard CRUD operations against the new service infrastructure. Its a simple service built-in Java Dropwizard using Hibernate ORM connecting to a PostgreSQL DB. The load test executed was also a pretty simple JMeter test that included a few hundred requests from a single node.
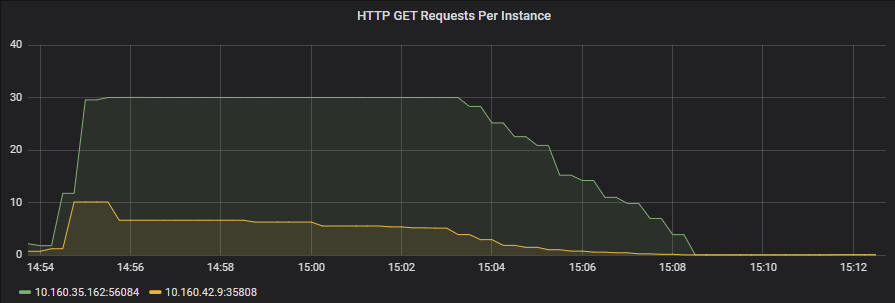
The chart metrics above were captured in Prometheus and charted for review in a Grafana dashboard. It shows a series for each node, and there are 2 nodes in total that clearly highlight the routing imbalance of the incoming HTTP Requests.
Other executions of the same test had similar results and in some cases were slightly more balanced but nothing drastically different. There are many inherent reasons that performing accurate or large scale load-tests in this way simply don’t make sense, including it being a single node, limited resources and how often the client actually resolves the DNS to the load balancer. Even the clients’ location in an AWS Availability Zone can impact the results. There are a few best practices to adhere to if you intend to obtain accurate load-testing results. Nevertheless, this is a cheap method in our CI/CD processes that offers us some measure of load, even if just in a more binary sense.
I was ready to chalk the issue up to the load testing inaccuracies with the belief that load might become better distributed with real traffic from multiple AZs and the real world. One of the team members, Ravi, was adamant that this was going to be a production concern that needed to be addressed before load was placed on it. Boy am I glad that Ravi pressed in. Further investigation showed a clear block on the number of pending threads within Hibernate (connections to the database). We knew the limit of the number of connection threads we expected a container to max out at and it then became obvious during the load test imbalance that some threads were timing out waiting for a connection from the pool.
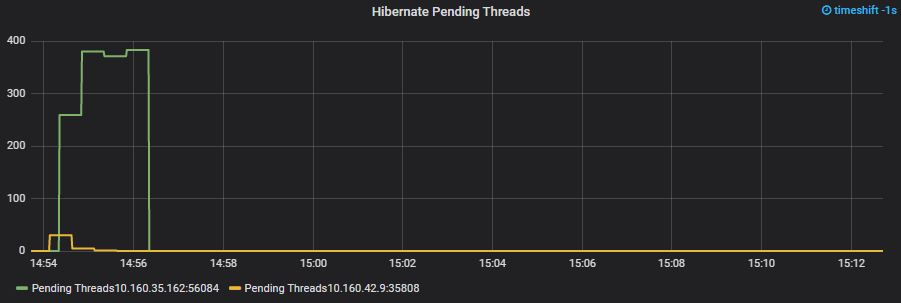
This is now a bit bigger of a problem and illustrates the effects of how a slight imbalance can cascade to a bigger issue. If you have a straightforward API with short and deterministically quick behavior and HTTP requests, the concern of ensuring you have an exactly balanced load-balancer is probably less interesting. The requests are too quick and require too little resources to worry about the slight imbalance. If your requests require a measurable amount of resources per request, a slight imbalance can begin to rock a bit and eventually spin out of the control with a lack of resources on individual container instances.
We began down the usual routes looking for reasons for the imbalance starting with the AWS Docs themselves. No luck. This service could not get much simpler. It was a simple CRUD API with a DB backend in a container behind an AWS ALB… what was going on?
The Solution
We spent a bit of time with our internal SRE and Cloud Operations teams discussing ALB routing algorithms and why the “round_robin” default configuration didn’t seem so round-robin at all on the ALB. At one point, one of the engineers, Troy, mentioned a new routing algorithm:
“Just curious have you looked into the new Least Outstanding Requests algorithm that was released in November? Not that my opinion matters but, this seems like it would ensure that regardless of the size or life of the request to the servers behind the ALB it would have a more balanced traffic pattern” (Troy).
The name “Least Outstanding Request” didn’t immediately illuminate the difference in the load balancer strategy to me, but it would soon enough, and Troy was dead on!
Rather than simply measuring the number of requests the ALB has sent to a node, it actually measures the number of completed requests it has sent to a node (and received back). This makes a ton of sense, especially in the behavior we saw above. What we thought was an imbalance of HTTP Requests was actually an imbalance of the amount of work or context an HTTP Request was performing. For example, one request would perform a simple GET operation and return very quickly. Another request would perform a write operation and take quite a few more connections and time to finish before returning. The metrics in the charts were measuring HTTP requests at a given time which begin to look more imbalanced or lop-sided as one node gets blocked, delaying the freeing up of connections, resources, impacting the next request on that node.
The change was simple. We updated the “target group” setting for “load_balancing.algorithm.type” to “least_outstanding_requests”, redeployed and began measuring results of the load-test again.
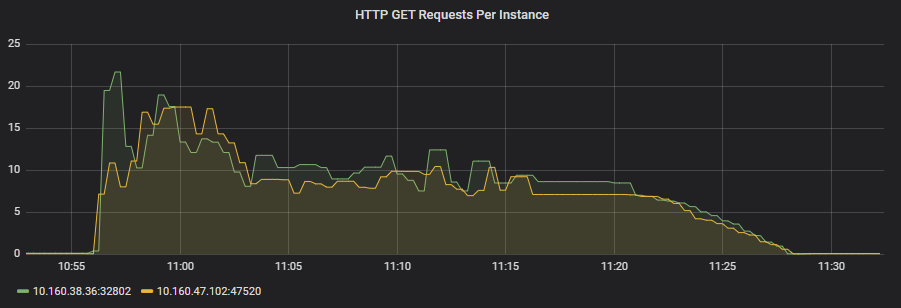
Just like that, the HTTP Requests began to look very balanced. The ALB was now considering the incompleted requests and distributing load differently.
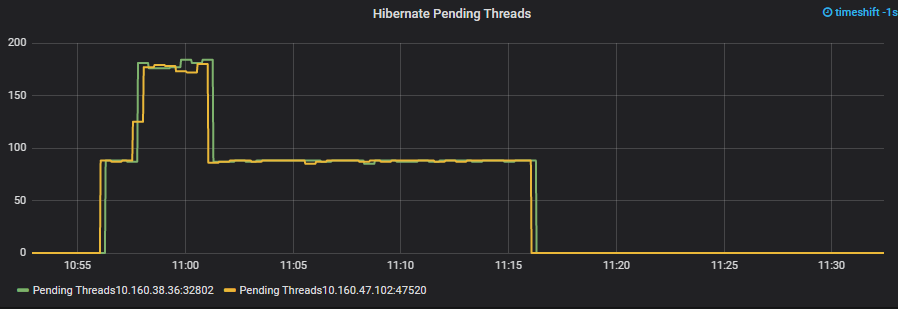
Similarly, the Hibernate pending threads looked EXACTLY like you’d hope between the two instances!
This was Ravi’s exact expression upon seeing the new results in Grafana:

With this one small ALB algorithm change, the throughput without dropping any connections went up by at least 50% without the need for anymore resource allotment. I’ll take that result any day of the week!
A Better Default Routing Algorithm?
Generally speaking this strategy of routing based on the least outstanding requests feels like a naturally better default than straight-up alternating round-robin. I’m generally interested now to review in more detail the round-robin effect of other services in our platform to determine if they are suffering a similar unnoticed behavior in some of their request lengths and resource utilization.
Definitely moving forward, applying this routing algorithm will be default for our services. That being said, I’d love to hear in the comments some examples where using the least outstanding requests algorithm simply doesn’t make sense?
Also cross-posted to SPS Tech Blog: https://spstech.micro.blog/2020/07/24/aws-alb-routing.html